Spiders¶
Spiders are web crawlers that use samples to extract data from the pages it visits.
Spider properties¶
You can access your spider’s properties by clicking the gear icon located right of your spider in the list on the left.
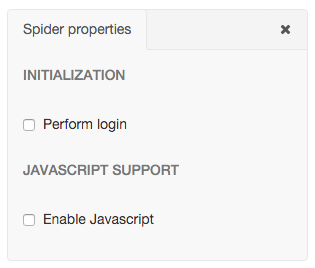
Configuring login details¶
If you need to log into a site, you can configure login details by ticking ‘Perform login’ in the spider properties menu. Here you can set the login URL, username and password.
Enabling JavaScript¶
You can enable JavaScript in your spider by ticking Enable JavaScript in the spider properties menu. Note that you’ll need to set the SPLASH_URL Scrapy setting to your [Splash](https://github.com/scrapinghub/splash) endpoint URL for JavaScript to work during the crawl.
Start pages and link crawling¶
Start pages are the initial URLs that Portia will visit to start the crawl. You can add and remove start pages on the left menu.
You can choose how Portia will follow links under LINK CRAWLING.
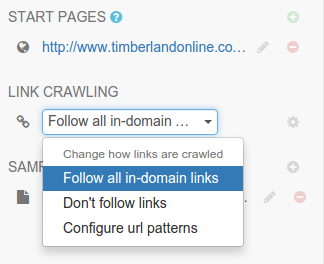
- Follow all in-domain links - follow all links under the same domain and subdomain.
- Don’t follow links - only visit start URLs.
- Configure url patterns - use regular expressions to choose which URLs to follow.
The Configure url patterns option lets you set follow and exclude patterns as well as choose whether to respect the nofollow attribute. Click the gear icon to show the link crawling options where you can set the follow/exclude patterns.
Running a spider¶
Portia will save your projects in slyd/data/projects. You can use portiacrawl to run a spider:
portiacrawl PROJECT_PATH SPIDER_NAME
where PROJECT_PATH is the path of the project and SPIDER_NAME is a spider that exists within that project. You can list the spiders for a project with the following:
portiacrawl PROJECT_PATH
Portia spiders are ultimately Scrapy spiders. You can pass Scrapy arguments when running with portiacrawl using the -a option. You can also specify a custom settings module using the --settings option. The Scrapy documentation contains full details on available options and settings.
Minimum items threshold¶
To avoid infinite crawling loops, Portia spiders check to see if the number of scraped items meet a minimum threshold over a given period of time. If not, the job is closed with slybot_fewitems_scraped outcome.
By default, the period of time is 3600 seconds and the threshold is 200 items scraped. This means if less than 200 items were scraped in the last 3600 seconds, the job will close.
You can set the period in seconds with the SLYCLOSE_SPIDER_CHECK_PERIOD setting, and the threshold number of items with the SLYCLOSE_SPIDER_PERIOD_ITEMS setting.